

Another title for this piece could be: How to stop AI from destroying trust between your organisation and clients.
We’ve all seen how powerful AI can be. It’s tempting to let it run and see what it produces. That might be fine for personal experiments, but not for high-stakes matters, especially in regulated sectors.
This is where we—humans—come in. When the stakes are high, when context is messy, or when trust is on the line, people need to design, guide, review improve and at key moments stop what the AI does. That approach is called human-in-the-loop (HITL).
But let’s clear up a common worry straight away: HITL does not mean “put a person everywhere”. The aim is balance. Use people where their input changes the outcome. Let the system run when tasks are routine, reversible, and safe. Get that balance right and you protect clients, move faster, and avoid needless cost and delay.
Why adding a human in the loop matters
Three simple reasons:
- Protect: prevent unsafe, biased, or non-compliant answers reaching clients or the public.
- Improve: add judgement, tone, and context the model cannot guarantee.
- Learn: turn real-world feedback into better content, rules, and prompts so quality improves over time.
If a review step does none of the above, remove it.
A quick test before adding any checkpoint
Ask five questions:
- Impact: What happens if the AI is wrong? Could it harm a client, breach policy, or dent your reputation?
- Reversibility: If an error slips through, can you fix it quickly and cheaply?
- Ambiguity: Does the task involve lots of context or edge cases?
- Controls: Do you already have guardrails, good sources, and basic checks in place?
- Speed: Will a human gate slow down something where speed is the value?
If impact and ambiguity are high, and mistakes are hard to fix, keep a human step. If impact is low, the task is easy to correct, and controls are strong, let it run and review by exception.
Where the real quality in AI comes from
Most quality in AI systems comes from what people do before and after launch, not from checking every message as it goes out.
Before launch: set the system up to succeed
- Choose trusted sources. Retire drafts and duplicates.
- Clean your content. Fix broken links and remove out-of-date documents.
- Write clear do’s and don’ts so behaviour is consistent.
- Build a small test set of real questions with ideal answers and name the single source of truth for each.
After launch: watch, learn, and improve
- Collect feedback. Thumbs up/down, short comments, and common follow-ups show what to fix.
- Sample sensibly. Review a small slice of outputs or chats each week.
- Tidy your sources. Update policies, remove stale items, tighten wording.
- Reduce checks over time as quality holds steady.
This is how we work at Kalisa. Clients upload checked, current, correct content. We add guardrails and grounding, then help teams test, learn, and improve, without placing a person between every user and every answer.
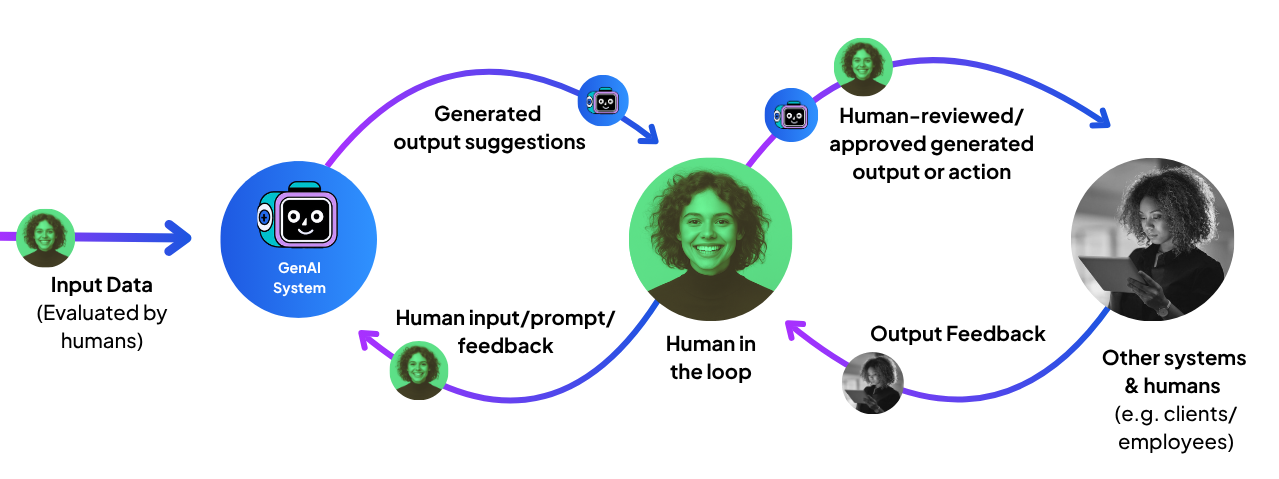
How do you check AI chat agent response quality?
Many organisations now use AI chat agents to support clients. It is one of the most common and useful AI cases, but adding a human to every reply is not practical. You cannot run a helpful chat service if each message waits for approval. So how do you protect quality and trust? Design for safe autonomy.
Your AI agents should:
- Answer only from approved sources, and show citations so users can verify.
- Apply confidence rules. If the system lacks solid support, it should not guess.
- Offer safe fallbacks. When confidence is low, say “We cannot confirm that from our records” and provide a policy link or contact route.
- Escalate by exception. If a user asks for advice beyond scope, disputes an answer, or requests an action with legal effect, hand off to a person with full context.
- Learn from users. Review flagged sessions and update content and instructions.
This approach delivers fast, reliable answers for most users, with people stepping in only when it truly matters. It is exactly how Kalisa’s AI Chat Agents are designed.
Where to add human review (and what “good” looks like)
High-stakes outputs
Examples: settlement letters, portfolio notes, clinical discharge summaries, public policy updates.
What to do: review at the last responsible moment. Confirm sources, scope, and tone. Record the decision. For major changes with legal effect, have two people sign off.
Brand and promise
Examples: website copy, proposals, investor updates, public statements.
What to do: have an editor or owner sign off early runs. Move to spot checks once quality is steady.
Data transformations that drive decisions
Examples: contract extraction that flows into operations; regulatory summaries used by teams.
What to do: start with more checks; reduce as error rates stay low and stable.
Safety, privacy, and fairness
Examples: open-ended content that might include personal data or sensitive themes.
What to do: let automated filters and checks run first. A person reviews only the items the system flags as risky or unclear.
What can you do when AI gets it wrong?
Even with strong controls, mistakes will happen. What protects trust is a calm, prompt, and transparent response. Treat service recovery as a standard process, not an emergency improvisation.
1. Acknowledge quickly
Show you are listening and take responsibility for fixing it. For example: “Thank you for flagging this. You are right to question it. We are reviewing and will come back with the correct information.”
Good practice
- Respond within the same working day (or within one hour for high-stakes matters).
- Thank the person for raising the issue.
- Avoid arguments or blame. Focus on the remedy.
2. Provide the correct path
Give the accurate answer or the safest next step:
- Provide the correct information, with a link to the source policy or document.
- If a decision is required, give the route to the right team (contact form, booking link, named mailbox).
- If the situation is urgent or sensitive, offer a call and a specific time window.
3. Make a visible fix
Show that you have removed the cause, not only patched the symptom:
- Update the source content (policy, FAQ, knowledge entry).
- Adjust the instruction (do’s and do nots) that governs the agent’s behaviour.
- Add or refine an example question and answer that reflects the edge case.
- If needed, add a temporary rule that blocks similar answers until the permanent fix is live.
4. Close the loop
Complete the interaction and record the learning:
- Confirm the fix and invite the client to check it.
- If there was a material impact (delay, inconvenience), consider a goodwill gesture that matches your policy.
Internally:
- Log the issue in a simple register: date, summary, client impact, fix applied, owner, follow-up date.
- Tag the incident type (factual error, outdated policy, unclear wording, scope issue).
- Share a brief note in your weekly review so others can avoid the same problem.
Bottom line
AI does a lot, but not everything. Put people where their judgement changes outcomes. Let the system run where tasks are safe, simple, and quick to fix. That balance protects trust, improves service, and keeps your teams focused on work that truly needs a human touch.
Powering the next generation of professional services
Kalisa offers everything you need to deliver valuable GenAI experiences to your clients and team.
- Chat agents with subject-matter expertise
- AI Workflows to automate business processes
- AI workspaces for your team
- Self-serve client portals and dashboards
- Subscriptions and monetisation
- Analytics to measure usage and engagement
- Securely combine public and private data
- API for systems integration
Book a free demo to see Kalisa in action
* This articles' cover image is generated by AI

%20(1).webp)
